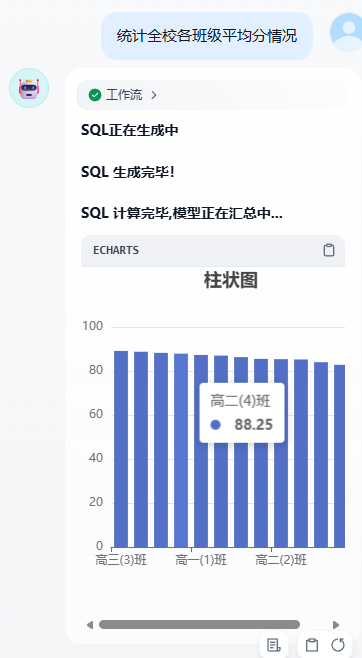
1.基本介绍
NLP2SQL(或称Text2SQL)是一种自然语言处理技术,旨在将自然语言问题转化为关系型数据库中可执行的结构化查询语言(Structured Query Language,SQL),从而实现对数据库的查询和交互。这项技术的核心目标是通过自然语言描述,无需用户具备SQL语法知识,即可完成复杂的数据库查询任务。
2.工具安装
本次工作流用到了几个工具:ECharts图表生成、database,需要提前对这些工具进行安装 
注意在安装Datatbase插件安装时,需要进行API Key的配置
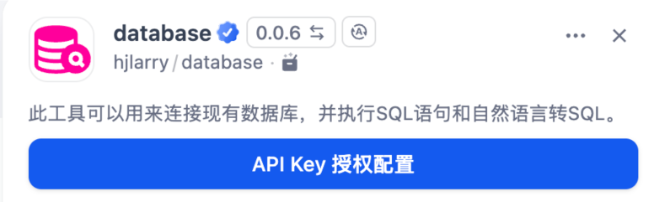
注意数据库URI的配置:
properties
mysql+pymysql://root:***@host.docker.internal:3306/###
其中***代表的是你的mysql登陆密码,其中###代表的是你要操作mysql数据库名称
mysql+pymysql://root:123456@host.docker.internal:3306/dify_test
服务器部署注意
1.Mysql启动方式
bash
docker run -d \
--name mysql-server \
#--network my-ai-net \ 规划网络
-p 172.20.0.1:3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 \
mysql:8.02.本地接入
关闭了公网3306接口,本地就必须通过ssh隧道操作
- 配置SSH选项卡:
- 主机:你的服务器公网 IP
- 端口:22
- 用户名/密码:登录这台 Ubuntu 服务器的账号密码
- 配置常规选项卡:
- 主机/IP地址:172.20.0.1
- 端口:3306
- 用户名:root
- 密码:123456
- 操作:测试连接成功后,新建一个名为 dify_test 的数据库。
3.连接database
这里因为mysql跑在服务器容器里,dify也跑在容器里直接使用
mysql+pymysql://root:123456@172.20.0.1:3306/dify_test在 Ubuntu 等 Linux 环境下,host.docker.internal 的 DNS 解析不如 Mac/Windows 丝滑,直接走docker虚拟网桥网关
3.整体流程
3.1开始节点
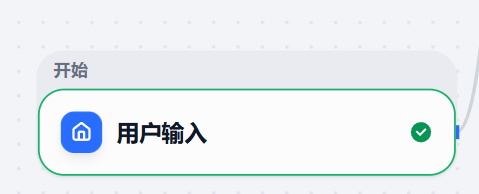
- 作用:用户输入:接受用户输出的问题
针对该节点默认输入即可,不用修改
3.2大模型:生成SQL查询语句
- 作用:根据用户提出的问题,生成SQL查询数组。
配置节点内容
1.模型选择
qwen3-max2.系统提示词
properties
## 角色
你是一个专业的SQL查询生成器,负责根据用户查询创建标准的MySQL数据库SQL语句。
## 任务
根据以下问题,生成一个格式清晰、结构明确的JSON数组,其中每个元素是一条合法且性能优化的MySQL查询语句。
### 表信息
表名:student_grades(学生成绩信息表)
### 字段说明
- id: 主键
- student_id: 学号
- student_name: 学生姓名
- class_name: 班级
- subject: 科目
- score: 分数
- exam_date: 考试日期
- semester: 学期
- grade: 年级
- created_at: 记录创建时间
- updated_at: 记录更新时间
### 输出要求
1. 根据用户的问题,生成最多10条直接关联问题的SQL查询语句。
2. 每条SQL应从不同分析角度(如按科目、班级、学期、年级等维度)切入,确保覆盖多维统计需求。
3. 所有SQL必须语法正确、可执行,并注重性能优化(如避免SELECT *,合理使用索引字段等)。
4. 若问题涉及多维统计(例如“各班各科平均分”),请为每个统计维度单独生成子查询。
5. 对于全量数据查询,必须按semester(学期)进行聚合或排序。
6. 最终输出必须是纯JSON数组格式,以 ```json 开头,以 ``` 结尾,不包含任何额外解释或文本,其中每个元素必须是对象,且仅包含一个字段:`"sql"`**(字符串类型),格式示例:
```json
[
{ "title": "统计XXX", "sql": "SELECT ...;" }
]
请严格按照上述格式和要求生成响应。3.用户提示词(主要给一下大模型一个用户提示词样例)
text
查询全校各科目平均分情况4.assistant提示词
- Few-shot示例
json
```json
[
{
"title": "统计全校各科目平均分",
"sql": "SELECT subject, ROUND(AVG(score), 2) AS avg_score FROM student_scores GROUP BY subject ORDER BY avg_score DESC;"
},
{
"title": "统计各科目及格率",
"sql": "SELECT subject, ROUND(COUNT(CASE WHEN score >= 60 THEN 1 END) * 100.0 / COUNT(*), 2) as pass_rate FROM student_scores GROUP BY subject ORDER BY pass_rate DESC;"
},
{
"title": "统计各科目成绩分布",
"sql": "SELECT subject, COUNT(CASE WHEN score >= 90 THEN 1 END) as excellent, COUNT(CASE WHEN score >= 75 AND score < 90 THEN 1 END) as good, COUNT(CASE WHEN score >= 60 AND score < 75 THEN 1 END) as pass, COUNT(CASE WHEN score < 60 THEN 1 END) as fail FROM student_scores GROUP BY subject;"
}
]
```4.user
properties
用户问题:{x}query3.3直接回复:SQL生产中
- 作用:对大模型生成的SQL语句给出提示:SQL正在生成中
这一步也可以省略,但是加上主要为了就是提醒
配置节点步骤
1.回复(注意要多出一个空行):
markdown
### SQL 正在生成中3.4代码执行:格式转换
- 作用:从大模型输出的字符串中提取和解析JSON数据,返回字典形式
配置节点步骤
1.输入变量:
input_string:LLM/{x}text2.代码
python
# 导入正则表达式模块,用于字符串模式匹配
import re
# 导入JSON模块,用于处理JSON数据
import json
# 定义函数,用于从输入字符串中提取和解析JSON数据,返回字典
def main(input_string: str) -> dict:
# 使用正则表达式查找并提取被 ```json 和 ``` 包裹的内容
pattern_match = re.search(r'```json\s*([\s\S]*?)\s*```', input_string)
# 如果没有找到匹配的内容
if not pattern_match:
raise ValueError("输入字符串中未找到有效的 JSON 数据")
# 提取匹配到的JSON字符串,并去除前后空白
json_content = pattern_match.group(1).strip()
# 尝试解析JSON字符串
try:
# 将提取的JSON字符串解析为Python字典
parsed_json = json.loads(json_content)
# 如果解析过程中发生JSON解码错误
except json.JSONDecodeError as err:
raise ValueError(f"JSON 解析失败: {err}")
# 返回一个包含解析结果的字典
return {
"result": parsed_json,
}3.输出
result-->Array[Object]3.5直接回复:SQL生成完毕
- 作用:对代码处理的结果给出提示:SQL生成完毕
配置节点步骤
1.设置(注意要多出一个空行):
### SQL 生成完毕!3.6循环迭代

- 作用:针对代码处理得到的字典结果里面的每个元素(SQL语句),循环执行后得到每个SQL的查询结果
配置节点步骤
1.输入:字典数据
代码执行/{x}resultArray[Object]2.输出:执行完sql的结果
SQL Execute/{x}jsonArray[Object]3.错误响应方法
移除错误输出3.7循环体内部:代码执行
- 作用:针对数组中的每个元素dict,提取字段
配置节点步骤
1.输入变量:
args:迭代/{x}item Object2.Pytchon代码
def main(args: dict) -> dict:
# 提取输入字典的字段
title = args.get("title", "")
sql = args.get("sql", "")
# 返回包含 title 和 sql 的字典
return {
"title": title,
"sql": sql
}3.输出:
sql:String
title:String3.8循环体内部:SQL执行
- 作用:执行SQL语句
配置节点步骤
1.输入变量
- SQL查询语句
循环体代码执行{x}sql3.9代码执行
- 作用:对循环迭代的结果进行格式转换
配置节点步骤
1.输入
args:迭代/{x}output Array[Object]2.代码:
def main(args) -> dict:
return {
"result": "".join(str(item) for item in args)
}3.输出
result:String3.10 直接回复: 结果汇总
- 作用:提示:SQL计算完毕,模型正在汇总中
配置节点步骤
1.设置(注意多出一个空行)
### SQL 计算完毕,模型正在汇总中...3.11 大模型:回复结果
- 作用:对查询结果进行汇总分析,另外把查询的结果ECHarts 图表组装需要的JSON格式数据。
配置节点步骤
1.模型
qwen3-max2.上下文:
处理循环体结果/{x}result String3.System提示词
### 角色
你是一个数据分析师,需要基于前一个模型生成的SQL语句及其执行结果,优先针对用户问题进行回答,确保回答内容紧扣主题不发散,同时对相关维度的数据进行分析,并以JSON格式输出给用户。
### 参数
- **用户输入**:{{#sys.query#}}
- **SQL 模型生成**:{{#llm.text#}}
- **SQL 查询结果**:{{#context#}}
### 图表使用场景
- 线性图:适用于展示趋势变化的数据,例如时间序列数据(如每月或每年的变化趋势)。
- 柱状图:适用于比较不同类别之间的数量或占比,例如各城市的占比情况。
- 饼状图:适用于展示整体组成部分及其比例,通常用于单维度的比例分布。
### 要求:
1. 优先回答用户问题,确保回答内容紧扣主题不发散。
2. 根据用户问题选择合适的线性图、柱状图或饼状图。
3. 将输出内容封装到JSON中,格式如下:
```json
{
"results": "用Markdown格式先回复用户问题,其他维度数据简单概括,但必须完整展示数据",
"ECHarts": "1", // 如果需要生成图表,则为 "1";否则为 "0"
"chartType": "线性图/柱状图/饼状图", // 图表类型(仅当 ECHarts 为 "1" 时提供)
"chartTitle": "图表标题", // 图表标题(仅当 ECHarts 为 "1" 时提供)
"chartData": "图表的数据,多个用;隔开", // 图表数据(仅当 ECHarts 为 "1" 时提供)
"chartXAxis": "图表的X轴,多个用;隔开" // 图表的X轴数据(仅当 ECHarts 为 "1" 时提供)
}
```
#### 注意事项:
- 如果查询结果适合生成图表,则将 ECHarts 设置为 "1",并补充 chartType、chartTitle、chartData 和 chartXAxis 字段。
- 如果查询结果不适合生成图表,则将 ECHarts 设置为 "0",并省略 chartType、chartTitle、chartData 和 chartXAxis 字段。
- 对于占比查询,必须使用饼状图进行展示,且在饼状图的 chartData 中返回百分比值。3.12 代码执行:结果处理
- 作用:对上面llm大语言模型处理的结果我们这里用代码执行生成echart
配置节点步骤
1.输入变量
args:LLM汇总结果/{x}text String2.代码:
import re
import json
def main(args: str) -> dict:
# 默认返回值
default_output = {
"results": "",
"ECHarts": "0",
"chartType": "",
"chartTitle": "",
"chartData": "",
"chartXAxis": ""
}
try:
# 使用正则表达式提取被 ```json 和 ``` 包裹的内容
match = re.search(r'```json\s*([\s\S]*?)\s*```', args)
if not match:
raise ValueError("输入字符串中未找到有效的 JSON 数据")
# 提取 JSON 字符串
json_str = match.group(1).strip()
# 将 JSON 字符串解析为 Python 字典
results_dict = json.loads(json_str)
except Exception as e:
# 如果解析失败,打印错误信息并返回默认输出
print(f"解析失败: {e}")
return default_output
# 检查是否包含 ECHarts 字段
if "ECHarts" not in results_dict:
results_dict["ECHarts"] = "0" # 默认设置为 "0"
# 根据 ECHarts 的值动态检查图表相关字段
if results_dict["ECHarts"] == "1":
required_chart_fields = ["chartType", "chartTitle", "chartData", "chartXAxis"]
for field in required_chart_fields:
if field not in results_dict:
results_dict[field] = "" # 自动补全缺失字段为空字符串
# 构造返回值
return {
"results": str(results_dict.get("results", "")),
"ECHarts": str(results_dict.get("ECHarts", "0")),
"chartType": str(results_dict.get("chartType", "")),
"chartTitle": str(results_dict.get("chartTitle", "")),
"chartData": str(results_dict.get("chartData", "")),
"chartXAxis": str(results_dict.get("chartXAxis", ""))
}3.输出
ECHarts:String
charTData:String
charTTitle:String
charTType:String
CharTXAxis:String
results:String3.13 条件分支
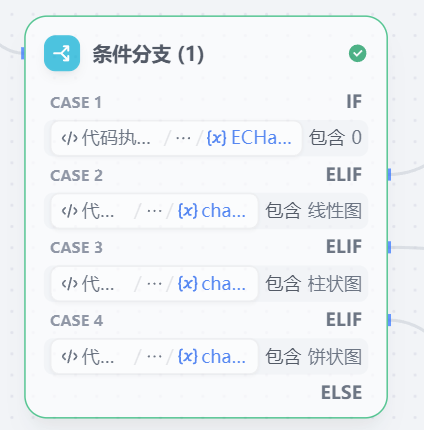
- 作用:考虑用户输入的信息:返回结果有线性图表、柱状图、饼图的输出,所以我们需要通过这个条件分支进行判断
配置节点步骤

3.14 Echarts图表生成
- 作用:这个地方就是主要是使用ECharts图表对线性图表、柱状图、饼图的输出
配置各节点步骤
注意:
- 无论是哪种图形,输入变量都是一样,都包括以下3个参数(饼图有点区别 它不是x 轴 而是换成分类)。
这里输入的参数有3个分别是:
1.标题:代码执行生成ECHART/{x}chartTitle
2.数据:代码执行生成ECHART/{x}chartData
3.x 轴(线性图、柱状图)/分类(饼状图):代码执行生成ECHART/{x}chartXAxis
3.15直接回复: 结果生成
- 作用:结果返回:分别对应线性图表、柱状图、饼图。
4.结果展示